How Cursor Indexes Your Code So Fast (Hint: It's Not Magic, It's a Tree!)
Let's talk about a common scenario. You're deep in the zone, coding away in your IDE. You're renaming files, refactoring functions, and adding new features. Your codebase is constantly changing.
Now, if you're using a modern AI-powered IDE like Cursor, you know it has a deep understanding of your entire project. It can answer questions about some_obscure_function.py or help you refactor code across ten different files. This is possible because it creates an "index" of your codebase on its servers.
But this leads to a critical question: with your code changing every few seconds, how does Cursor keep its server-side index up-to-date without constantly re-uploading and re-processing your entire project?
A naive approach would be to re-index everything every few minutes. But that's a terrible idea.
- It’s Expensive: Indexing is a computationally heavy task. Doing it constantly would burn through server resources.
- It’s Slow: Sending your entire (encrypted) codebase over the internet every three minutes would be a massive bandwidth hog and make the experience laggy.
So, how do they do it? The secret lies in a clever, elegant, and surprisingly simple data structure from the world of cryptography: the Merkle Tree.
What on Earth is a Merkle Tree?
Forget the scary name for a second. Think of a Merkle Tree as a system for creating a single, unique "fingerprint" for an entire folder of files.
Here’s the core idea:
- Every file gets its own unique fingerprint, called a cryptographic hash. If even one character in the file changes, the hash changes completely.
- Every folder gets its own fingerprint, which is created by combining the fingerprints of the files and sub-folders directly inside it.
- This process continues all the way up to the top-level folder of your project, which ends up with one single, ultimate fingerprint: the Merkle Root.
This Merkle Root is magical. It represents the exact state of your entire codebase at a specific moment. If any file changes, the root hash will change.
Let's visualize this with a simple project structure. Imagine we have a project with four files in two folders.
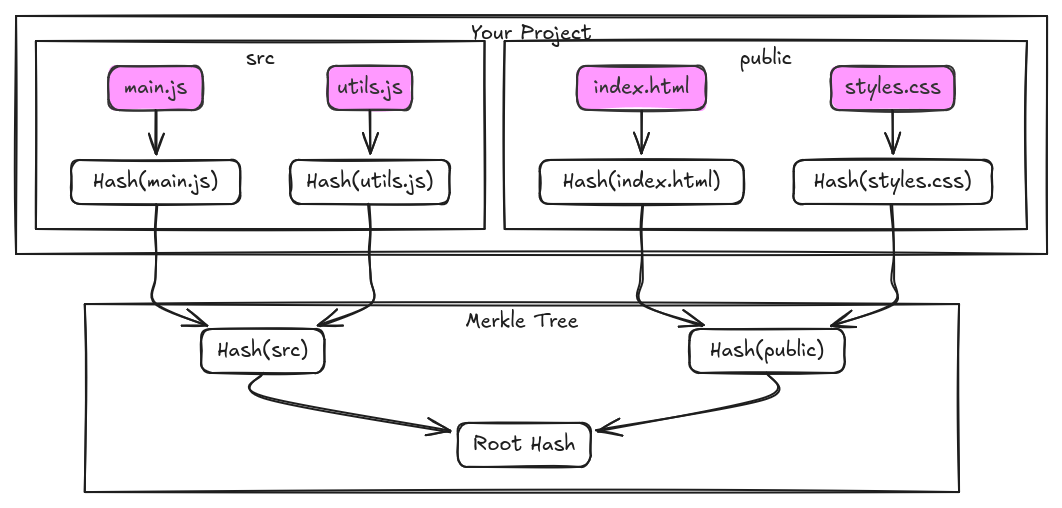
- The Leaves: At the bottom, we have our files. Each one is hashed. Let's call them
H1,H2,H3, andH4. - The Nodes: The
srcfolder's hash,Hash(src), is a combination ofH1andH2. Thepublicfolder's hash,Hash(public), is a combination ofH3andH4. - The Root: The final
Root Hashis a combination ofHash(src)andHash(public). This single hash is the fingerprint for the whole project.
How Cursor Puts This Tree to Work
Okay, theory is cool, but how does this solve our indexing problem?
Cursor is clever. It maintains two Merkle Trees:
- The Client Tree: Your machine (the client) builds a Merkle Tree based on your local files. This is the absolute "source of truth."
- The Server Tree: Cursor's server builds its own Merkle Tree based on the files it has already indexed.
Every three minutes, a sync process kicks in. But instead of sending all the files, the client just sends its Root Hash to the server.
The server compares the client's Root Hash with its own.
- If the hashes match, great! Nothing has changed. The server does nothing. Sync over.
- If the hashes don't match... this is where the magic happens.
Spotting the Difference: The Power of Tree Traversal
Let's say you just saved a change to index.html. Your local client immediately recalculates its Merkle Tree.
- The hash for
index.htmlchanges. - This causes the hash for the
publicfolder to change. - Which, in turn, causes the
Root Hashto change.
Now, the sync begins.
The Comparison Flowchart:
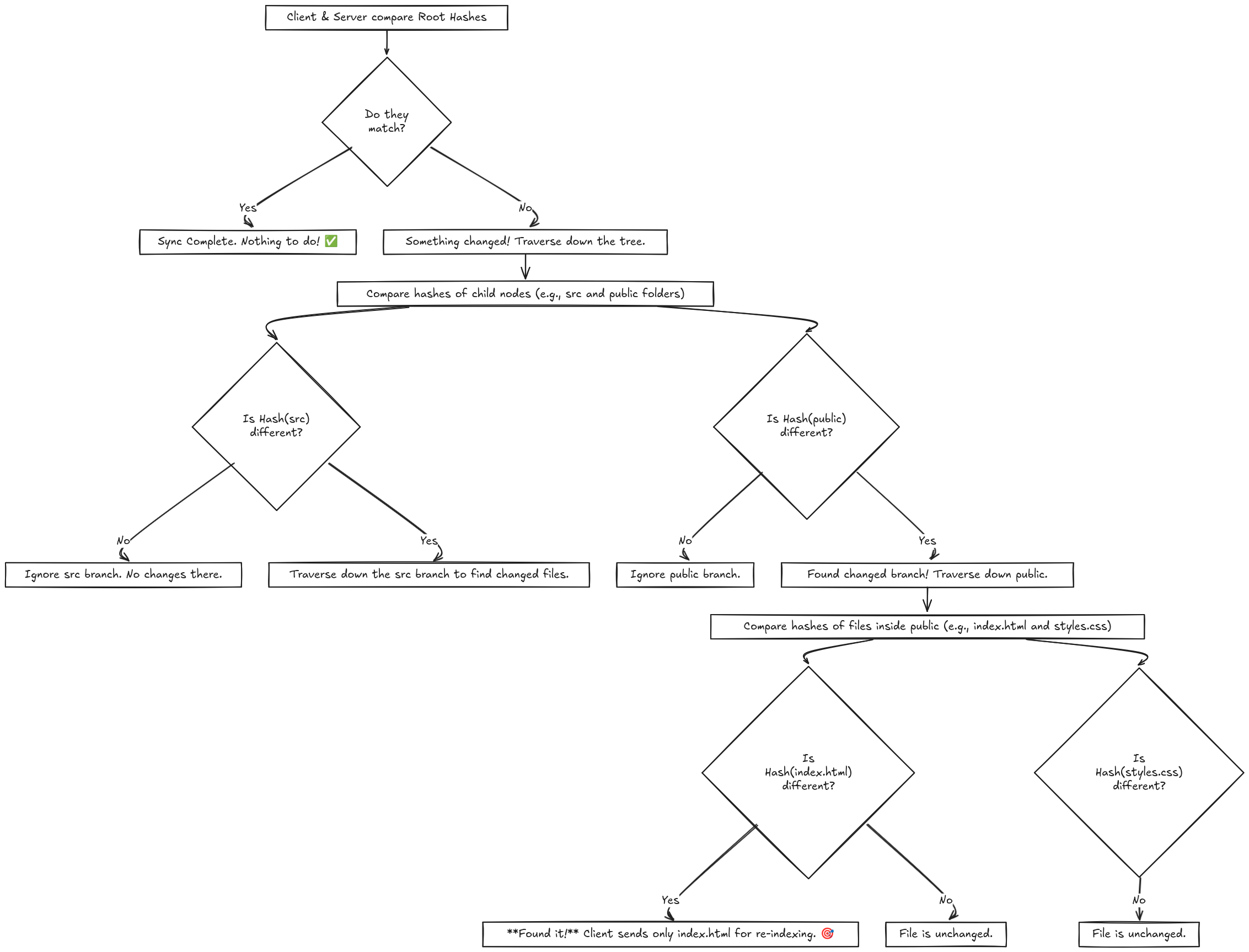
By walking down the tree and comparing hashes at each level, the server can pinpoint the exact file or files that have changed with surgical precision. It doesn't need to look inside the src folder at all, because its hash matched!
It only needs you to send the new version of index.html. Not the whole project, not even the whole folder. Just the one tiny file that was modified.
This is incredibly efficient.
The Real-World Payoff
Think about your daily workflow. You shut down your laptop for the night. The next morning, you run git pull and fetch a dozen changes from your teammates.
Without a Merkle Tree, your IDE would have to blindly re-upload and re-index a huge chunk of your project.
With the Merkle Tree, Cursor does the quick hash comparison, immediately identifies the 12 files that changed, and only syncs those. This saves your time, your bandwidth, and Cursor's server costs, all while keeping your AI assistant perfectly in sync with your codebase.
So the next time you see Cursor's indexing status update in a flash, you'll know the beautiful computer science at play. It's not just some brute-force check; it's the quiet, efficient elegance of a Merkle Tree, doing its job perfectly in the background.