Lessons from CommitChronicle for CommitCraft
June 11, 2025
3 min read
538 words
Research Notes
I was working on how to make CommitCraft better and was searching for a solid dataset I could use for evaluations (and maybe fine-tuning models) when I came across this interesting paper—and it’s...

I was working on how to make CommitCraft better and was searching for a solid dataset I could use for evaluations (and maybe fine-tuning models) when I came across this interesting paper—and it’s packed with insights that could directly inform our design. Here are a few more key takeaways, in simple terms:
Why reframing CMG as completion can boost CommitCraft
- Completion is dramatically easier than cold-start generation. For the best model, the average B-Norm score jumps from 16.9 in the generation setting to 27.2 when the user has already typed half of the message .
- Exact-match rates skyrocket with even a small prefix. CodeT5’s ExactMatch@1 goes from 10.90% (0% prefix) to 45.35% with just 25% of the message provided, and to 49.94% at 50% .
- Practitioners already love completion. Just like IDE code-completion or email suggestions, developers say they’d prefer incremental “next-word” help over a full black-box message .
💡
The point sounds No-brainer ,just not sure how i will fit this into present ux of CommitCraft yet
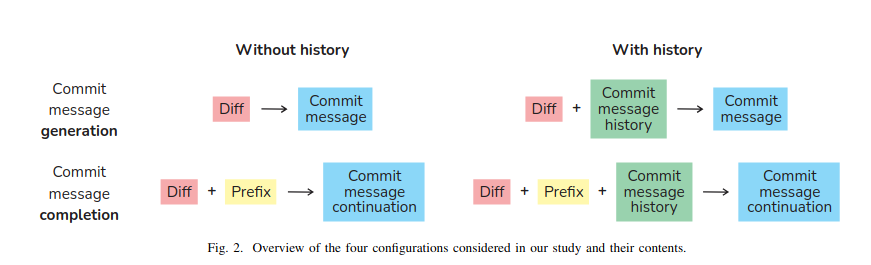
History-aware inputs help match your style
- Better full-message generation. Appending recent commit messages to the model’s input raises CMG models’ B-Norm from 15.3 to 16.9 in the zero-prefix (generation) setting .
- Mixed results for completion. When you give the model a prefix to finish, adding history barely moves—and sometimes slightly hurts—performance, suggesting that nailing the first tokens remains the hard part .
- LLMs still benefit from history across the board. GPT-3.5-turbo sees gains in both generation and completion when supplied with just one past commit message .
CommitChronicle: a truly real-world dataset
- Massive and multilingual. They collected 10.7 million commits across 20 programming languages from about 12 000 GitHub repos, keeping author IDs, timestamps, diffs, and raw messages intact .
- Minimal filtering so you see the messy tail. After dropping bots (∼165 K commits, 1.52%) and outliers, they still retain 38.98% of the original 27 million commits—crucial for learning realistic patterns .
- Common filters would throw away most data. If you applied the usual “diff ≤ 100 tokens” filter, you’d lose 84% of commits; verb-direct-object messages would cut 64%; single-sentence summaries another 17% .
Specialized CMG models vs. general LLMs
- Short suggestions: CMG wins. On a 4 K-commit LLM-test subset with 25% prefix, CodeT5+history scores a B-Norm of 21.11, whereas GPT-3.5-turbo only hits 13.24 .
- Long, detailed messages: gap narrows. GPT-3.5 often exhausts its max-token limit by default, writing richer continuations that start to rival CMG models on longer completions .
Paper’s key contributions (and what i can reuse)
- Reframing commit-message generation as completion, with a clear formalization and evaluation setup.
- History-aware modeling by appending past messages to the input.
- CommitChronicle, a 10.7 M-commit, history-rich, multilingual dataset.
- Comprehensive comparisons of three SOTA CMG models (CodeT5, RACE, CodeReviewer) and GPT-3.5-turbo across generation vs. completion and history vs. no-history modes . mayeb i can extend it or have my own benchmarks with the latest models present
Bottom line for CommitCraft:
– Build your UI around incremental completion, not just full-message proposals.
– Leverage each user’s history to tune for their style—at least for full-generation scenarios.
– Train and evaluate on unfiltered, “messy” data (e.g. CommitChronicle) so your metrics reflect real-world usage, not an idealized subset.